Project Management
Case studies
This section lists the cases which I carried out as part of my digital product lead employment at a company referred to throughout as JX, where my product management experience largely comes from. JX is an online media outlet publishing daily briefings on a variety of cultural topics, focussing on young creatives. Each part poses to me a series of questions, to which I respond by describing the real-life scenarios in the form of case studies (CS).
Download additional materials
Case studies (from this page, as a PDF)
Case study materials (Figma)
1. Knowledge and experience. Planning and delivering product improvements using industry-standard tools and techniques. Managing backlogs and roadmaps, balancing priorities and dependencies, and mitigating risks
CS1. Planning and delivery
To illustrate my approach in this area, I can use a case study of an online film festival (FF) which JX had organised during the COVID-19 lockdown period between March and October 2021 to increase the audience and visibility of the journal. Production requirements for FF included creating a new website section to host a series of 35 online screenings, implementation of a streaming platform and design of the associated promotion materials.
I have approached the project as a series of the following tasks:
To create a detailed requirements document based on stakeholder meetings.
To do the research for the film streaming options.
To coordinate the design and production of the FF landing pages, as well as film streaming platform integration.
To coordinate the delivery of marketing collateral.

Fig. 1. Production phases and releases.
The project workgroup consisted of the producer from the editorial side, two developers and two designers. When building the roadmap, I have split the production efforts into three versions: open call, film festival and awards. (Fig. 1) These corresponded to the JX landing pages which had to be released at three points: before the festival, at festival start and when the winners were announced. I planned and coordinated the delivery phases according to the production best practice: discovery (including opportunity, planning and estimation), design (including wireframes and production-ready mock-ups), development and testing (Fig. 2). Such treatment had allowed me to effectively track the tasks pertaining to each release.
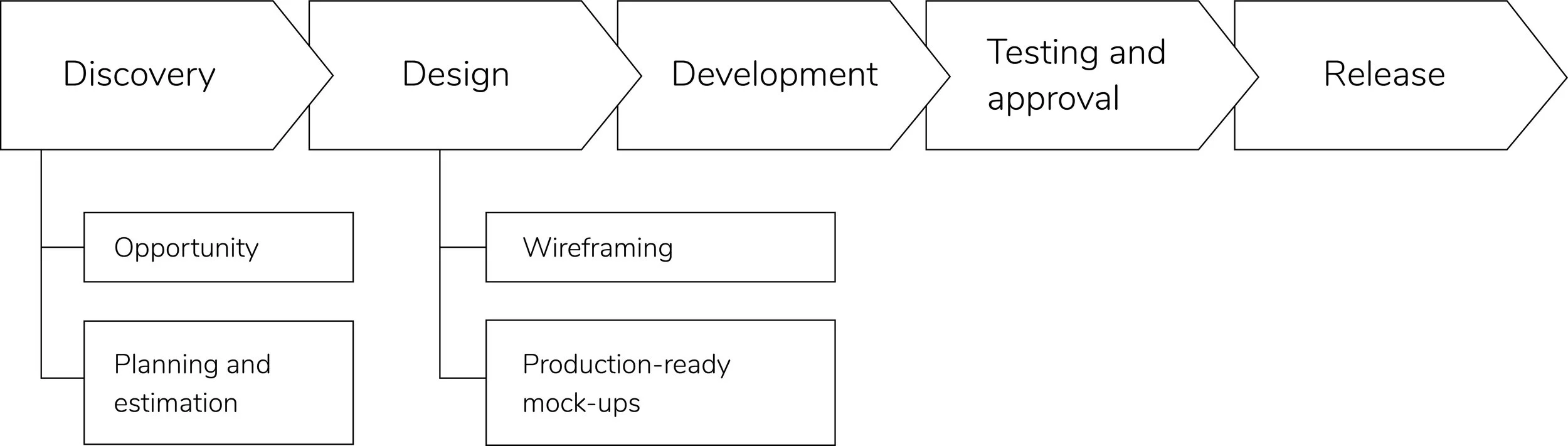
Fig. 2. The production pipeline.
CS2. The archive project
This case study stands apart from other activities in my fieldwork because it was conducted as a separate project after my empirical research was finished, and in fact after the official closure of JX as the media channel in 2022, due to the geopolitical tensions between Russia and Ukraine, which were the main sites of the journal’s content. The core stakeholder requirement for the project was to transform JX to a digital archive, with an aim to preserve its legacy. As a former product lead for JX, I was involved with the delivery of the archive with the new team, trying to bridge some of the major gaps in knowledge to maintain the required traction. At the start of the project, I came up with the project proposal that included a user story in the following form:
As [an academic institution user] interested in the history and culture of [this geopolitical region],
[I want to] have a versatile database search tool
[so that I can] easily find the collection of materials on the topic I’m interested in
The user story formulated as such has largely instructed the project requirements, such as easy accessibility of required content and the three main user activities of searching, sorting and browsing the archive entries. To facilitate them, I proposed to add three new features to the existing website. First, a new home page that would no longer have recent publications and instead offer a prominent search field. Second, the expanded Advanced Search landing page that would feature filtering by date and tag in addition to existing category, location and content search. (See CS12 for more details on original Elastic Search work.) Lastly, the new Catalogue page, which would act as the website’s table of contents and list all the JX categories, locations and tags. Following from the proposal, I have created a product map (Fig. 5) that would help explain how these new features would sit within the existing JX structure. On the map, the pages would be functionally divided into Sort pages (Home page, Advanced search and Catalogue), Browse pages (such as Travel, Photography and other Category pages) and Content pages containing the actual editorial content.

Fig. 5. Digital archive product map.
After presenting the work scope to the stakeholders and the discussion about the milestones and budgets, I came up with the project work breakdown structure in the form of the timeline (Fig. 6). The timeline would feature the two main types of work to carry out, design and development, and have split the production efforts per feature in terms of their dependencies. For example, the home page and updates to the navigation had to be done prior to the work on the Elastic Search or the Catalogue. At that point, stakeholders had also agreed to deliver the work in two phases so that we could launch and test the new home page and navigation as a first step, and deliver the rest of the work in the second step. It is important to note that this timeline was only created as the initial indication of which work was required, and was subsequently used by the IT contractors (DX) who were assigned to do the work, to create their own project documents, estimates and to allocate resources. During the actual execution of the project, the work scope was optimised and made more compact, which resulted in delivering all required features sooner – the contract with DX was closed on December 5th 2022.

Fig. 6. The archive project timeline in the proposal phase.
Production-wise, the key problem on this project was that we no longer had the previous team members, the back-end and two front-end developers, which led to the inevitable loss of momentum. This meant that the back-end engineer and webmaster freshly enlisted on the project could not simply start building where the old production team left off, even though we had ensured that all the required system access and product documentation were provided. Some of the features, such as top navigation, had to be re-created from the ground up, and some of the content work that seemed easy to do, such as re-assigning the tags and categories, had required extensive investigation and in the end had to be excluded from the project scope due to required extensive redesign of the product database architecture. The main outcome of the case study was that despite my concerns, the loss of momentum did not seriously damage the overall team performance. The onboarding was quick and seamless, and even though the new features created regression problems in places where they were not compatible with the existing code base, most of them were addressed within the project scope.
CS3. The use of tools to balance priorities and mitigate the risks
In the context of the FF project as described in CS1, I have balanced the priorities and mitigated the risks with the three industry grade tools: Smartsheet, Jira and Confluence. While Smartsheet worked well for stakeholders, Jira was ideal for development, and linking these two tools allowed me to create a fluent conversation across the different organisation strata. Lastly, Confluence was used as a technical documentation space available for all.
Smartsheet. The roadmap I created in this online Gantt suite had allowed stakeholders, producers and marketing to estimate the efforts and evaluate the risks before taking any action. For FF, I used Smartsheet to set the timeframes for the three releases, populated each with associated production, editorial and marketing activities, and assigned tasks to relevant team members. This has allowed me to report based on person, team, task type, or project stage. Where possible, I have linked the tasks to corresponding Jira issues.
Jira. As a tool for managing support tickets, Jira was a good fit for balancing priorities and dependencies in delivery of FF, once the strategy was approved on the stakeholder level. I have used Jira for the following tasks:
Composing user stories for all aspects of development, for example: ‘produce video for the banner’, ‘create an anchor link to festival passes’, ‘stabilise the open call page performance’. Each user story contained the requirements, rationale, current context and any additional information.
Backlog grooming: organising the backlog stories in order of their priority, based on the consensus within the organisation and the production team. Decommission or de-prioritise the stories which were no longer relevant.
Sprints. Opening, closing and reporting on sprints in two-week intervals. Constructing upcoming sprints with stories from the top of the backlog, depending on team velocity and story point estimates.
Releases. Tethering Jira releases to pull requests in GitHub, which the developers used for version control. Each release deployment was marked with the corresponding Jira release tag. After each release, I ran a retrospective with the FF workgroup to address any issues, celebrate the achievements and discuss the work approaches.
Confluence. Creating pages for initial requirements, meeting minutes, feedback, retrospectives, and supporting the developers in writing up the technical details, such as streaming platform integration.
CS4. Annual planning
In the first quarter of 2022 at JX, I was responsible for creating a draft high-level roadmap. This task included:
Gathering what was already known about the projects planned for that year, compiling draft requirement documents and creating wireframes which would show essential features.
Compiling the draft roadmap while discussing the collected materials with the developers, who would advise on the rough time estimates.
Adjusting the roadmap draft so that all team members have a steady flow of work.
Stakeholder presentation, paying extra care to the responses in terms of the delivery priorities and projected deadlines.
Revisiting the roadmap in view of the feedback and sharing across the team as the initial version of the workable plan. The emphasis here was that the plan is in no way set in stone and would be further adjusted as the projects take shape.
As a result, the team had an understanding of the composition of each project throughout the year, which allowed them to organise their work accordingly.
CS5. User research
At JX, I have conducted user research as part of the main navigation redesign project, to understand the goals and aims of such redesign. In this case, I was only tasked with surveying company employees because a brief audience survey had been done shortly before. I carried out two group surveys of staff in both company’s offices, and a series of face-to-face semi-structured interviews with stakeholders. In the second stage, I have identified that these conversations were, in fact, not sufficient because the group was already too familiar with the product, and a more thorough user testing and more audience surveys were required. Knowing that JX lacked the resources to carry out such testing, I organised a meeting of JX staff and a third-party business analyst consultancy, who came up with a proposal for creating a viable user research programme. The approval of the initiative, however, was delayed for reasons outside of my control, and given the project deadlines, we had to complete the initial version of the new main navigation based solely on the audit results already at hand (see CS7 and CS12 for more details). Given such limitations, we could still argue the successful translation of user needs into tangible outcomes, since we have created a search function and a sidebar menu where none of those existed before. Going forward, I had persisted in advocating a continuous user research protocol, to be able to better instruct further UX improvements.
CS6. Discussions with technical teams
I structured communication within the production unit at JX around the weekly 30–40 minute meetings, during which each team player reported on current progress. The weekly rather than daily cadence made sense because most team members were working part-time. Moreover, some production team members also attended the daily editorial stand-ups, and also had a chance to communicate about particular projects in project-specific meetings. My tasks included hosting of meetings, creating the backlog of Jira tickets, updating the roadmap and articulating the pain points for further discussion beyond our team. I was also responsible for deciding on the optimal approach to the scope of the upcoming week in terms of the task implications and trade-offs of maintenance vis-à-vis new feature development. Such an approach to team discussions contributed to the confidence of each of our colleagues in their work and aided developing a sense of trust within the team as a whole.
CS7. Reliability and security
Following a website performance failure due to a suspected attack in October 2021, I had decided to start an initiative to improve the platform security. I had then obtained approval to hire a freelance DevOps specialist, with whom we have formed an intensive working relationship over the period of the following five months. Together, we have implemented a range of security measures across the several key areas:
Content delivery network (Cloudflare CDN): updates to security settings, firewall and error pages.
Amazon Web Services infrastructure hosting (AWS): updates to users, groups and permissions.
AWS: scaling down the infrastructure to optimise the costs.
AWS: create a proposal and cost estimates for high availability architecture and auto-scaling to increase product reliability.
JX content management system: drafting the password rotation policy, updating users, implementing captcha.
Google Workspace: updating user groups and users, two-factor authentication, security updates on user devices.
Physical server: migration of data to the cloud storage (Google Drive). The migration was supplemented by creating the automated backup suite, briefing the staff on the new Drive usage and decommissioning of old equipment.
Hardware support: revising the annual rolling contract with hardware support company (ITX) to understand what we are paying for.
The benefits of the initiative were as follows:
AWS optimisation brought a 65% reduction in monthly costs without any losses in service quality.
Using Drive and backups improved compliance with company data storage policy.
More detailed analytics on Cloudflare; the rest of its optimisation required more time before verifying the results.
Captcha reduced the number of failed login attempts to the company’s services (no specific KPIs), which suggested previous malicious attacks.
Hardware support: we have found that we no longer required ITX services because the nature of JX operations had changed too much over the years – no physical server, no physical location, etc. This meant further reduction in support costs.
CS8. UX
My approach does not include the formal handling of UX, and up to this point has been lightweight, which can be demonstrated through the following example. In the navigation redesign case mentioned in CS4, JX has worked with an external senior design consultant. The consultant provided the static designs, videos that demonstrated animations and the key effects, along with the interactive prototypes. My role was, often together with the project manager, to test the prototypes on the range of devices, to make sure that the page transitions correspond to the approved user journeys, get the client approvals and to give feedback to the designer. While this approach to UX was culturally appropriate to JX, I’m interested in further developing my command of formal UX techniques.
CS9. Analytics
My job duties up to now did not include the in-depth data analytics as such, and was limited to using the two tools:
AWS. I had created dashboards for CPU and memory load balancing trends to understand the capacity demands, had been monitoring the alarms and accessed the Cost Explorer to report on the details of monthly billing. Overall, I have a basic familiarity with AWS reports.
Cloudflare. I mainly reviewed the dashboards for audience statistics, however my knowledge of this platform so far is limited.
CS10. Quality Assurance (QA) and User Acceptance Testing (UAT)
In the JX migration process to the new version of the platform in 2018–2019, I was a primary point of contact to the third-party IT suppliers (DX) who were commissioned to carry out the technical parts of the job. In this project, I was involved with QA and UAT as follows:
QA. The backlog for this project was managed by DX, and I primarily addressed the tickets where their quality assurance staff required further commentary from JX.
UAT. I approached the UAT process for each round of testing in the following way: once the new release was ready for the UAT, it would be made available on the staging environment. I would then confirm the testing session times with the dedicated team members (the UAT team). Next, they would log in and leave their comments in the shared spreadsheet. For more intensive sessions, we sometimes found it easier to schedule a conference call, during which the UAT team would test the product, and I would fill out the sheet. During the sessions, I also made sure that we tested from different geographical locations and on different devices, using the testing emulation tools such as Lambda where needed. After completing each round of feedback, I would have a call with DX’s account managers to discuss the test results.
2. Communication. Writing high-level product requirement documents and feature specifications suitable for technical implementation
CS11. Technical documentation
High-level documentation. During the JX platform migration to AWS as the new cloud infrastructure in April 2020, I was, among other things, responsible for delivery of the project’s technical documentation. I had personally authored the high-level documentation pages, while the developers and DevOps were documenting the corresponding technical parts they were working on. This had resulted in a section of the company’s Confluence wiki, detailing various aspects of migration and implementation of Continuous Integration: ELK stack creation, Jenkins pipelines, Git workflow, AWS environment schemas, how-to for Nginx and PHP configuration, and more.
Feature specifications. A case of ElasticSearch implementation, discussed in CS12, is an example of me writing the feature specifications suitable for technical implementation. For the Search, after the initial part of the work, including the discovery and visual concept was done, I had prepared a draft of technical specifications and organised a meeting with the DX account manager, with whom I discussed and further refined the specs list. DX would then come back with their own roadmap and the cost estimates, which would allow me to incorporate it into my planning and approvals routine.
Data to knowledge collection flow. The ongoing method for collecting and integrating the project data has consisted of a few key stages, as demonstrated in Fig. 3.
Taking notes in meetings and following up each meeting with an email stating the date, attendees and key takeaways.
Create tickets based on the work items identified in the notes. The main purpose of the ticket is to generate a list of requirements. It has a list of decisions which were made and a list of actions to take, where each action is linked to a specific individual to follow up with. Decisions, actions and requirements are updated from meeting to meeting as the work progresses.
In the end of each release or other milestone, we run a retrospective that allows us to identify failures as well as successes.
After the retrospective, all data is transferred from Jira to a more permanent storage, where it is systematised in a way that would be easier to access later or by individuals who were not involved in the work previously. Lastly, based on the resulting knowledge base, I submit an annual report at the end of each year.

Fig. 3. Data collection flow.
CS12. Stakeholder communication
When delivering the security suite described in CS6, I was reporting the progress in weekly management meetings to the business owner, creative director, editor-in-chief, head of operations and head of marketing. Here, the low degree of technical familiarity among the executive staff was a challenge that I addressed by focusing not on the technology itself, but on budget and time considerations. I would avoid using any technical jargon. As an example, for the old and failing server problem, I had presented a few different solutions and their associated costs. One option would be to replace the old server with a new box, the other – less costly and more secure – would be to decommission and migrate the data to cloud storage. This made it easy for the stakeholders to evaluate the trade-offs and take the decision quickly.
3. Initiative and problem-solving. Proactively identify and deliver on areas for improvement, for example, gaps in product functionality, the product development process itself, or opportunities for training and support
CS13. Initiative
I have proactively identified the JX website search feature as underperforming in a few respects, both search quality and UX, and came up with the updated requirements that included a more thorough search plug-in (Elastic Search), a prominent search field in the top navigation and the ability to filter search results by the category, location and content type. This proposal was supported by marketing, who saw this initiative as an opportunity to increase the visibility of the JX’s rich archive database. The staff designer was also inspired by the project and came up with a set of visual concepts, adding such ideas as the visual search pop-up box and the results counters. Next, I had split the search delivery into phases (Fig. 4), and have found an opportunity to hire a back-end engineer for the implementation of Elastic Search plug-in after obtaining the approvals on the new navigation designs. As a result, despite the missing protocol for KPI tracking, business owners had evaluated the overall accessibility of the website content as improved and marketing had confirmed the boost in targeted promotions.

Fig. 4. A proposed roadmap for Elastic Search Phase 1.
CS14. Governance approvals
In my role at JX, I was not directly involved in governance approvals, and due to the small size of JX itself, no navigation of complex structure was necessary. However, such negotiations is a direction that I see myself shifting towards in the coming years.
4. Liaison and networking. Building effective relationships and influencing without direct authority across a busy, decentralised organisation
CS15. Building effective relationships
Link-building was part and parcel of my work with the third-party IT suppliers (DX), mentioned in CS9 and CS10, where I saw my goal as maintaining a warm and friendly sense of collaboration. I took this relationship seriously, not only because DX was a key source of our talent, but also due to the strong belief in continuous discovery in software product work. On the latter point, DX and JX had agreed that the ongoing nature of review and response was best addressed via an ongoing relationship with the trusted co-workers. My way of successfully building trust was through frequent and professional communication that would maintain a colleague to colleague, rather than client to contractor relationship. Since DX was scattered around different locations, I have used every opportunity to visit their offices and see them in person.
CS16. Influencing
The 2018 YY project at JX presented a case where I used my influencing abilities to address the silos issue. The project involved production of several short films, which meant that key members of the team had to be away on site making the footage. However, the silo effect meant that little of the project information had seeped into the production team, and we were faced with the dilemma of creating an online presentation of the films on a short deadline and with no prior planning. Without having a direct authority to change the silo situation, I was, however, able to influence the wider company culture over a period of time so that as we went along, the practice of using shared roadmaps and collective discussions and planning of releases became a part of the usual approach. The tangible result were the new weekly management meetings, which provided the opportunity for heads of all departments to communicate and report on their progress.
Participate in digital industry events, keeping up to date with digital product trends and advances
CS17. Trends and industry involvement
Currently, I am completing my PhD in cultural studies in product management. My academic investigation is explained by my interest in current product management trends, the key literature and the desire to develop a long-term research trajectory to be able to contribute to my professional field.
I have conducted university seminars, spoken at conferences and published work in a peer-reviewed journal. These three facts may come as evidence of my ability for teaching, presentation and writing.
The academic activity serves as evidence of my ability to provide:
Learning: I have conducted university seminars, leaving the students happy, according to a follow-up online survey.
Publicly present my ideas: I spoke at the Historical Materialism conference in London, which was followed by a lively Q&A.
Ability to write persuasively: my piece for the Computational Culture journal was published after successfully passing the peer review.
5. Service delivery. Supporting the end-to-end customer experience through an iterative product feedback cycle. Troubleshooting technical issues reported and liaising with the development team to prioritise fixes and solutions
CS18. Customer experience
At JX, the situation of issue reporting, prioritisation and troubleshooting can be illustrated through the case of so-called ‘broken pages’. After the migration to the new version of the platform was completed in the early stage of my employment at JX, we discovered that dozens of old pages had manually adjusted code which meant that the layouts appeared distorted, and there was no automated way of fixing them. My task was to establish a routine that would enable the support staff to deal with the problem in a systematic, longitudinal manner. I have come up with the following protocol: the editorial team, who did not work in Jira, would log in the faulty URL and the description of the issue in the spreadsheet shared online. From there, developers would address the small fixes, and I would write up the stories for larger ones – for example, where the slideshow gallery plug-in had to be changed for an entirely new one. This way we covered a lot of ground in a short amount of time. After we had dealt with the urgent matters, I moved on to address a larger issue – that the ‘broken pages’ were deployed into production in the first place. This concern resulted in the implementation of the three environments: development, testing and production, which allowed capturing most bugs before publishing to the live version of the website.
Identifying opportunities and creating resources to support and engage users, including product documentation and delivering workshops, training, and/or demos
CS19. Workshops
For identifying opportunities, I primarily analysed the competition and the user research data available, such as described in CS4 and CS12. I have also delivered the workshops whenever a new tool or practice was introduced in our workflow. For example, as the team was familiarising itself with the new Continuous Delivery workflow, I have conducted a workshop on story mapping, a software production method discussed in Chapter 4. This included creating a shared online whiteboard, a tool simple enough to use by technical and non-technical staff. Once everyone was logged in, I would introduce the concept of thinking about new features in terms of storytelling and the process of splitting complex scenarios into releases. This explanation was followed by the practical part, during which the participants would collectively create a story map of their morning routine, with different scenarios. The outcome of the workshop had an effect that had a vast resonance in the team – people had a great grasp of the concept of versioning after the workshop, and referred to the event later as a useful learning experience.
6. Decision-making. Balancing advocating for your ideas and remaining open-minded to different or opposing views. Discerning when and how to challenge assertively, yet being able to “disagree and commit”
CS20. Advocating change
One case of a ‘disagree and commit’ situation I had encountered was during the security and reliability initiative as described in CS6. As part of the initiative, our research had shown that the organisation had used considerably more CPU and memory than was needed because the generic infrastructure settings of the initial installation were not revisited and adjusted regularly. I have come up with a proposal to optimise the infrastructure for present requirements. My proposal, however, was initially rejected, due to the stakeholder’s engagement in other aspects of the business. I have met this decision with an open mind, in the hope that a chance to come back to the proposal will present itself. And indeed, some time later, the business priorities have changed, and we had a new brief to reduce the costs, which allowed us to proceed with the earlier proposal. This resulted in a 65% AWS cost reduction.
Backing up ideas with data and ensuring product direction decisions support organisational strategic objectives
CS21. Backing up ideas with data
The data I had used to back up my arguments at JX usually concerned budgets and time required to complete the work (as seen in CS11). In the case of FF as described in CS1, my task was to present such data to editorial and marketing so that they could advise on which streaming platform to use. The objectives included ability for ticket sales, setting up the film streaming times and accessibility of audience metrics. To achieve this, I have done a comparison of costs, between a bespoke streaming platform vis-à-vis the out-of-the-box solutions. After a cursory investigation revealed that renting a ready-made platform would incur considerably fewer costs, I conducted further comparison among the third-party vendors, attending their demos and assessing the compatibility of their offers to our requirements. This process resulted with a decision on a specific service, backed up by the appropriate budget and functionality, which had fully supported the organisations’ strategic objectives.
CS22. JX server migration
Another case of the proposal backed by the data had been the JX physical server migration, which was undertaken in November and December 2021 and was carried out in a fashion close to the topological case study explained in this chapter. The data and the organisation’s strategic objectives came together during the server downtime incident in the last week of October 2021, which was followed by the complaint from the JX staff that the IT maintenance contractors (ITX, also discussed in CS7) were late in responding to JX’s queries and neglected their contractual obligations, which resulted in the server downtime that lasted for over five days, even though the power blackout itself that caused the downtime was only a few hours in duration. The first requirement that I had to deal with stated plainly that we were not happy with ITX and had to find a new one. When faced with a requirement like this, however, my first instinct was to collect and organise the data by reconstructing the incident and examining the current contract with ITX to draft a more precise list of requirements. Without doing this, I wouldn’t have been able to tell which services we needed to seek to replace, and whether we required those services at all. Meanwhile, the complaint was raised after the incident was over, which meant that I was not aware of all the details and had to begin by creating a timeline that would reflect the sequence of events that caused the complaint. This was done by examining the emails and conducting the three brief interviews with the finance manager, the operations manager who were engaged in the conversation with ITX and the client’s web developer, who had travelled to the JX offices to switch the equipment off and back on. At the end of this phase, I had the following Gantt chart (Fig. 25).
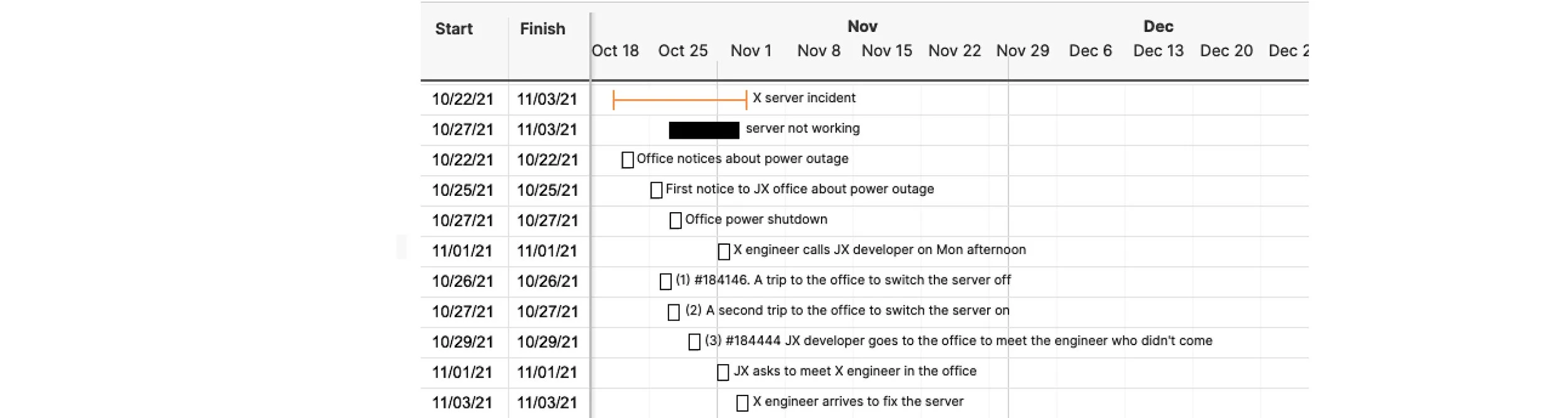
Fig. 7. The first reconstruction of the server incident.
This, however, only led me to believe that there was no fault of ITX, but instead the server downtime had lasted for five days for the reason that no JX staff was available in specific moments, and the communication was handled by different people, which led to inevitable delays. In addition, I have learnt from the contract that ITX was providing us with the services of three different kinds: server backups and maintenance, software support and hardware support.
As the next step, which signalled the beginning of phase 2 of the case study research method (case-based work), had a planning session with the DevOps specialist, during which it became clear that the problem was not in changing ITX to another contractor. Rather, it was in the performance of the server itself, which was low because it had been in operation for a long time and needed a replacement. Instead, we then proposed to migrate the server online, and create a Team Drive on Google, a web service that members of JX staff were already familiar with, and thus would be happy to switch to. This solution also solved the security problem, since it meant that staff would no longer seek to save their files in an unregulated way, and have all the files stored via the company’s assets. This solution was welcomed by the JX staff, which had allowed the DevOps and me to proceed. The following steps were included, as shown in Fig. 8 alongside the reconstruction of the initial incident: a trip to the office and sorting out the access rights; remote server access, creating the required policies: cloud storage, backup policy and the new folder hierarchy. Lastly, we had to create an exit strategy from the current IT support we had with ITX, which was the original requirement, however now we saw that there might be a business risk in cancelling the contract with them completely, due to the possible unpredictable circumstances that no-one could deal with apart from them.

Fig. 8. JX physical server migration.
At this point, we could propose to amend the agreement, and take out the clauses that covered the server maintenance and backups, since that was now moved to the cloud service, and we no longer needed any software and hardware maintenance, since this was covered by the respective manufacturers. Thus, the project reached its closing stage, which resulted in the following activities: workshops with JX staff on using the new cloud-hosted server file system, and the proposal to ITX with the new requirement for ad hoc maintenance. In terms of topological continuities, we could observe that a more transparent relation was now in place between the business and the organisational planes of the technological system, since the role of the IT contractor was clarified and the unnecessary step of storing the files in the resource that required additional maintenance and resources was eliminated.