Chapter 5. The governance and the falling cost of computation
The systems theory approach, as described in this study up to now, views an organisation through its temporal and spatial patterns of operation. In terms of temporal flow, the organisation generally processes the inputs, such as resources and customer orders, into the outputs, such as products and services. In terms of space, the organisation establishes itself topologically by splitting its internal protocols from the ones of the external environment, as Mezzadra and Neilson observe, imposing the boundary as the tool for legal ordering and enactment of market relations, and acts to maintain the equilibrium between the two so that the boundary remains intact.1 It may be viable to suggest governance here as an organisational practice that makes the conversion of inputs to outputs possible by regulating the split between the organisation’s inside and outside. Along the same split, there are corporate and business kinds of governance. The former deals with matters such as policy compliance and consistency with the audit practice, while the latter is concerned with business performance and the creation of value. The practical job of governance, to use David Farley’s formulation, is largely the responsibility of the boards and executive staff which have the authority to provide the strategic direction and verify that the organisation’s resources are used responsibly.2 In this chapter, I am concerned with the changes that governance needs to undergo in the face of the extreme complexity of things, the production of which it has to regulate – a discussion, which is appropriate for the final chapter of the thesis because its matters relate my research to the wider body of the digital humanities and cultural studies more generally.
The chapter revolves around three main themes: the falling cost of computation, the problematics of assimilation of knowledge and the coordination specificity in distributed governance, which I approach by splitting the discussion into three sections. In the first section, I introduce the trend of the falling cost of computation by establishing what computation means for production, why its costs tend to diminish, and what kind of benefits and risks the trend presents. I find that the falling cost of computation arises from the exponential increase in the computational capacity of hardware and tends to escalate the complexity of the production system as the software capitalist tendency seeks to valorise the computational surplus. The increasing computational capacity, as the second section discovers, has a direct impact on the system assimilation of knowledge through increasing the agent’s cognitive load, or the amount of mental effort they have to exert to support the production flow. In the situation where the complexity pressure cannot be alleviated, the agents treat the incoming knowledge parsimoniously, by codifying and abstracting it – that is, by applying the categorisation and other patterning rules to the knowledge so that it becomes easier to navigate. The more successful rules and patterns tend to propagate throughout the system and evolve to become operative on the levels of teams and organisations. In the third section, I treat the parsimony principle as the evidence of self-organisation that makes the governance distributed, and concomitantly as the key effect that complexity has on administrations. The advantage of self-organisation is that it is more resilient in the face of change, as the new methods get continuously promoted from the agent level upwards in case they appear to be more adapted to the changes of the environment. The high adaptability explains why the systems that realise the distributed governance model are often referred to in complexity management theory as complex adaptive systems – their complexity refers to self-organisation, and adaptability points to their resilience. The aim of presenting the organisation as a complex adaptive system is to verify that such presentation makes it possible to think strategically about complexity avoidance in the context of the falling cost of computation.
Computation in production
The ubiquitous use of computation in all the processes of software capitalism confronts the present study with a necessity to account, however briefly, for the consequences that computation’s key tendency – the disruptive diminishing of its cost – has on the production lifecycle and the complexity forces therein. To summarise what we have learnt about computation so far, it makes sense to revisit its definition adopted for the present research, and the benefits traditionally ascribed to it, prior to delving into a more detailed discussion of the associated risks. I define computation in terms of Brian Arthur’s argument of the counterposition between algebra and computation in economic theory. To Arthur, economics had historically used algebraic statements and thus had evolved to be described with nouns, becoming largely equipped to think quantitatively, which supports exact and reliable explanations.3 Computation is a process of executing a set of instructions or operations, or an algorithm, within a system. Unlike algebra, it lacks the certainty of interpretations but instead enables a focus on the domain under investigation in terms of its processes.
The key shift here is from a method that uses nouns to one that uses verbs, which is also present in compositional methodology. As Lury notes, the present form of the verb in the description of method emphasises the involvement of the event of the application of method into the matters of research, and therefore activates the situation as a problem.4 And, as Arthur contends, the use of verbs can offer a fuller description of complex systems through the heterogeneity of agent positions, through shifting emphasis from objects to actions and describing the models in uncertain circumstances not only with statements but also with processes and flows they are involved in. Computation operates with an if–then boolean logic and is, therefore, something that is far more useful for negotiations in the problem spaces of software production systems, which run simultaneously through the organisation’s lines of communication, its deployment pipeline and its business value stream.
The benefits of depreciating computation
The professional DevOps literature the previous chapters looked at follows a path of a predominantly technical discussion of software that focuses on the advantages of the expected ongoing increase in the computational capacity of the hardware. It is usually implied that the existing issues of negotiations within the problem space of production will be easier to solve as the drop in the costs of computation continues, along with the associated upgrades to the production equipment and the new conceptual approaches to production, such as Continuous Deployment and team topology, discussed in previous chapters. The benefits thus offered can be split into two categories, occurring either on the individual or on the group level. On the individual level, there are data processing payoffs, which see the increase in efficiency of agents, whether human, non-human, organisational, or other types. Second, there are data transmission benefits, which look at the improvements in exchanges between the agents. In the case of hardware microprocessors as discussed by Intel’s Gordon Moore, the two categories are mutually reinforcing because, as Max Boisot notes, the higher speed of processing also means higher throughput in transmission.5
Furthermore, the higher rates in data processing and transmission result in corresponding increases in knowledge diffusion and a higher bandwidth effect. On the one hand, the knowledge diffusion ratio indicates how easy it is to access knowledge: the lower the cost of computation, the larger the number of people to whom this knowledge is available. The high rate of diffusion may mean that the epistemic infrastructure can be made accessible to all relevant members of the production event, subject to user management policy. This, in turn, makes viable the continuously integrated production lifecycle model as simultaneously the carrier of the business value and the deployments of software stock produced. On the other hand, the bandwidth effect, as theorised by Max Boisot, implies a more dense and rich character of communication in general and digital media distribution in particular.6 Where previously the communication required more effort on the side of stakeholders and was constrained to specific formats, such as voice-only calls or print-outs of visual materials, the higher bandwidth allowed negotiations using face-to-face video calls and screen sharing. Additionally, a higher bandwidth meant that the problems that could previously only be solved by the means of non-digital delivery could now be addressed via computation-based means. For example, the published media initially required the physical distribution of printed materials to the audience. The increase in bandwidth has enabled a gradual shift in solving the problem to the realm of the digital – starting with the use of electronic communication and digital printing, then by switching to fully digital online production and distribution without any printing at all.
The traction crisis diagram from Chapter 1 (Fig. 1) can be revisited in this context to illustrate how complexity appears in situations where processing and transmission are rising, depending on how the organisation follows this up (Fig. 16). In the first instance, the governance stays fully or partially centralised, which means retaining some of the complexity effects because of the inability to keep up with the increasing pressure to audit the increased knowledge traffic. The other choice is to go distributed, which balances the complexity out through scalability of control, such as through designing the problem space architectures to be self-similar throughout the various abstraction levels.
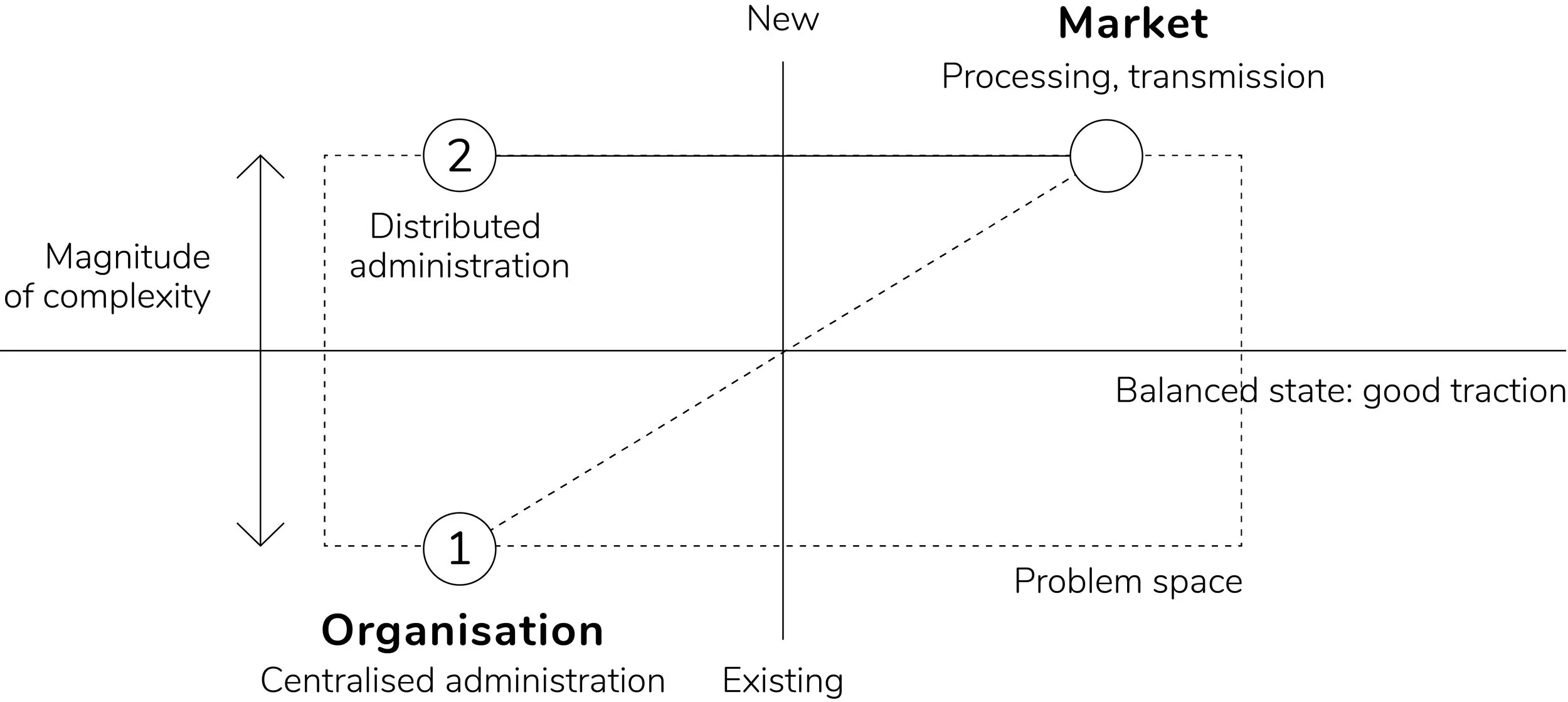
Fig. 16. Traction balance using distributed administration.
The risks of depreciating computation
Despite such benefits of the tendency of the cost of computation to fall, the interest of this chapter lies in going in the opposite direction and outlining any disadvantages and risks. Is it possible that low-cost computation introduces complexity that could have otherwise been avoided? Keeping in mind Melvin Conway’s observation that complexity in a software system tends to be reflected in the organisation’s communications, locating the failures and understanding their causes should help shed light on the risks cheap computation introduces to the organisation and market domains. Some of the more prominent disruptive effects of the cheapening of computation that this study looks at are the software crises. It should be noted that while the software crisis as a term is equally applicable to all the crises which have occurred within the software production practices, this in no way implies that the substance of the crisis itself has never changed. Quite on the contrary, this is precisely because the crisis always emerged in a different shape, which made it cause enough distress to be regarded as a crisis all over again. The examples this thesis looks at are telling yet by no means aimed at providing an exhaustive list. In the ‘big iron’ era of mainframe computers such as the ones described by Frederick Brooks, the software crisis was manifest in the organisational reverse salients that led to staff increases and clogging of communication channels, ultimately causing the organisation to stumble in the allegorical tar pit. At a later stage, once Agile thinking started becoming widespread, the software crisis shifted to signify the impossibility of integration. There was no longer a shortage of code libraries and other components, and the main stumbling block has become the maintaining of parts, keeping them compatible and tracking the changes. This has become known as technical debt, similar both to real financial debt and to the previous software crisis, threatening organisations to go bankrupt due to the inability to maintain their own code. Once the disciplines of code reviews and refactoring were established, it became possible for the organisation once again to position its efforts orthogonally to the complexity forces and to avoid disintegration under their unbearable burden.
However, neither the Agile workflow nor the code review practice stopped the complexity effects from emerging in a different form. As Chapter 1 aimed to explain, the systemic approach to production comes together with a centralised model of governance enacted via the intra-organisational management structure. As Chapter 4 discussed further, such structure is necessary for epistemological and economical facilitation of audit. In other words, since the audit is only possible of something auditable, the internal system’s management is implemented in such a way as to provide the organisational setting in which the audit is possible. Review no longer has to deal with the full complexity of software production systems, but only with the management tasked with reproducing the organisational structure all the way down with the auditability in mind. While being effective enough in dealing with auditable matters, the downside of such an approach is that anything that falls outside of the audit capabilities also cannot be accounted for when negotiating problems, and therefore is not a part of the problem space of production. Meanwhile, there can never be a shortage of new factors of production that cannot be accounted for, brought about by the new and more capacious hardware, in alignment with Moore’s Law. This is, the chapter argues, where the further disruptions and software crises come from. With this in mind, the chapter aims to analyse the disruptions along the axes established before as the conditions for system cohesion – change, momentum and control.
The tendency of the cost of computation to fall is a reversal of Moore’s Law which puts an emphasis on the value created by the hardware, as a tool of production, in relation to the cost of production of said hardware. In other words, since the computational capacity of microchips is growing, it becomes cheaper to produce a microchip with the same computational power, and the amount of computation that in the era of 1950s mainframes required large-scale investments into operations and infrastructure is now possible with the relatively low-cost solutions.7 To understand why the falling cost of computation is a risk, it is best to turn to the early problematisation of it by a pioneer computer scientist, Douglas Engelbart. Widely credited as the inventor of the computer interface, throughout his career, Engelbart was broadly engaged in developing a comprehensive framework that would tie together social and technical aspects of personal computing.
In the 1994 interview, Engelbart had warned that the real social danger of technology is its disruptive expansion: ‘the rapidity with which really dramatic scale changes are occurring in what the capabilities of technology are, are such that by the time that really gets integrated into the whole, our whole social human system there’s a lot of adaptation to be made’8 In the current industry sources, this concern is echoed by the business analyst Azeem Azhar, who argues that businesses that consider the falling computation costs are better positioned to take advantage of its effects – with the primary benefit of not being crushed under the mounting complexity of production. ’One primary input for a company is its ability to process information. One of the main costs to processing that data is computation. And the cost of computation didn’t rise each year, it declined rapidly…’9For software capitalism, processing of information is the key function of any business. The firms, Azhar observes, ‘are largely not cut out to develop at an exponential pace, and in the face of rapid societal change.’10 Yet, as this study saw up to this point, slow adaptation is, in fact, a part of an organisation’s survival tactics, since it promotes the organisation’s healthy traction, or deployment-to-integration ratio between its EIAC and the problem space of production. Good traction lets the business model generate sufficient outputs while being able to manage the inevitable incoming changes and stay internally coherent. The balancing of the three aspects of traction – momentum, change and control, becomes increasingly challenging in the face of the exponential fall of computation costs. The key challenge, as the next section uncovers, comes from the cognition processes associated with the ways in which the agents treat the incoming flow of new knowledge.
Data, information and assimilation of knowledge
To unpack the specificity of the assimilation of knowledge in its relation to complexity, it now is useful to examine the principle of requisite variety, developed in early cybernetics and frequently employed in organisation studies to describe the behaviour of agents in complex systems. Formulated by the pioneer cybernetician Ross Ashby, the so-called Ashby’s Law of requisite variety states that to survive, the system needs to be able to develop a response mechanism which is capable of countering the full spectrum of stimuli coming from its environment – save for the noise.11 If the system does not produce enough variety, it fails to secure the resources it needs to survive and eventually fossilises. If, on the contrary, it overreacts and spends excessive resources to produce more responses than the external stimuli require, it risks disintegration. Once the system achieves the point of requisite variety, it is selective enough and achieves sufficient parsimony to be able to allow for a response relevant to its environment. What such a presentation reveals about the software production system, is that the interactions of agents are necessarily mediated via the problem space of production and that in fact, two integration processes take place – on the one hand, the knowledge is assimilated by the agents from the problem space, and on the other hand, the results of the problem negotiations are integrated into the EIAC. Such integrative processes allow the system to maintain the complexity requisite to its purpose.
In the agent-level integration (Fig. 17) developed by the complexity management scholar Max Boisot, the agent acquires the stimuli inputs from the problem space of production and uses a range of perceptual filters informed by the context of the organisational culture and the agent’s own expertise to recognise the data from noise.12 In the next step, the agent’s conceptual filters are applied to detect the patterns in the acquired data to filter the relevant items, which collectively become the information. Lastly, the information gets assimilated as knowledge via the agent’s personal considerations based on its stored mental models and organisation-specific values that have pre-existing relations with the information inputs. Even though the three types of production inputs – data, information and knowledge – may seem like the various stages of gradation from signal to noise, in fact, the distinction is context-specific: what is noise in one moment of an agent’s cognition can be a relevant piece of information in a different context.

Fig. 17. Integration as the process of assimilation of knowledge inventory by the agent. Adapted from: Boisot and Canals in Boisot in Boisot et al., 2007: 20.
The inputs therefore are best seen in terms of their utility and the impact they bear on the agent’s behaviour. The utility is different for each of the three inputs. The advantage of data is that it can carry any sort of evidence without discrimination. The benefit of information is that it can inform the agent about what can be expected in terms of knowledge it may bring. The utility of knowledge itself is in its ability to modify the agent’s actions in a way that makes it better adapt to the environment. As Boisot finds out, knowledge is the set of beliefs held by an intelligent agent that can be modified by the reception of new information and on which the agent is disposed to act.13 It should be noted that in the problem space, proximity is related to such behaviour modification. While Fig. 17 portrays the relation between the individual agent and the whole of the problem space in an abstract way, the problem space itself is not homogenous and the agents are more likely to receive most stimuli from the agents located close to them, albeit through the mediation of the problem space.
As a second consideration, besides the integration process from the problem space by the agent, there exists the integration that assimilates the negotiated knowledge from the problem space of production to the EIAC. Such integration is widely discussed in professional DevOps literature under the general rubric of Continuous Integration. In a move opposite to the Continuous Deployment discussed earlier, Continuous Integration is seen as the operations’ best practice that requires the system code to be frequently integrated into a shared repository. The difference between continuous approaches to deployment and integration, for the present discussion, is that Continuous Deployment makes the system available for the stakeholders, while Continuous Integration deals with the maintenance of infrastructure and is aimed at making sure that EIAC is always up to speed with all the recent changes. In the practical sense, Continuous Integration means that the whole of the system’s code is getting synchronised once every few minutes to eliminate the risk of failure when merging big batches of code which might not be compatible and carry the potential of breaking the system. Discussion of the epistemic infrastructure in Chapter 3 may lead to thinking that once the infrastructure for knowledge is in place, and the system for capturing and accessing the knowledge is established, the actual process of knowledge acquisition becomes a rather practical consideration. However, what organisations quickly realise is that not only the infrastructure needs to be constantly realigned with the knowledge contained in the organisation, as this thesis pointed out before, but the knowledge itself is not something that can in fact be recorded into the provided framework. To understand this problem, some consideration has to be given to the differences between knowledge and information, as it is discussed in Brown and Duguid.14 First, information is more independent and resides outside of the space of action, that is, has an infrastructural quality. Knowledge is more active, it needs to be associated with the knower, the practitioner or other sort of agent – in the case of the problem space of production, they are stakeholders, including users, business owners and production staff. Second, information, as more self-contained, is easier to transfer. It can be written down in code, placed into the database, and can be referenced. Knowledge, on the contrary, is something that cannot be pointed to directly – instead, the referral needs to be to the person who knows a particular thing. This makes the whole discussion about access rights and permissions more complicated. Third, knowledge is something that requires assimilation. For example, when a specific record is accessed in the company’s support wiki page by a member of staff who accesses it to decide on a given case, it needs to become knowledge through the process of understanding – to be achieved, knowledge requires a certain degree of commitment. For example, ‘I have information, but I don’t understand it’ is possible, while ‘I know, but I don’t understand’ is not.15
Consideration of these properties of knowledge helps to clarify why epistemic infrastructure is not sufficient on its own, as the repository of software system possibilities. Once organised and deployed, it still remains, albeit informative, rigorously structured and topologically oriented. On the other hand, the problem space, as the activities within it evolve, becomes increasingly dependent on infrastructure. The organisation in software capitalism is primarily a learning initiative, which means that it depends for its operations on human and intellectual capital circulation, manifest in the acquisition of knowledge.16 Therefore, it is imperative for it to see the assimilation of knowledge, or its integration, as the primary function. In other words, if the deployment function is the essence of the EIAC, then the integration function is the essence of the problem space of production. Simultaneously, the software capitalist formation at stake here, which is also frequently referred to as knowledgeable or cognitive, makes it quite prominent to the businesses that an employee’s mental capacity is a valuable company asset, and that the knowledge is contained in the minds of the teams, rather than in the databases, since, as we saw, knowledge is not something that exists outside of the knowing subject. Departing from the industrial mode of production that only viewed living labour as adding value in its capacity as a machine operator and its maintenance, in the new form of production the value depends on the human ability to learn. Two noticeable moves make the treatment of knowledge more explicit in IT production. On the one hand, there is a practice of making the information relevant and easily accessible, which for the present context is referred to as differentiation. On the other hand, there is the explicit incorporation of the practices of finding, organising and presenting information into the problem space of production, which requires establishing a more thorough understanding of the process of integration. To zoom in on the specificities of the differentiation and integration, it is necessary to start from a wider discussion of the cognitive load metric, which both events could be accessed with.
Cognitive load and governance of the knowable
The topological becoming of problems in problem spaces not only clarifies their mapping to epistemic infrastructure but also activates the mechanisms of governance over access to what is known. The governance regime implies a specific set of values based on the capacity to know, establishing a protocol for knowability that operates within a specific imaginary. As Lury puts it, ‘problems always become topologically, with-in and out-with problem spaces’ and there is ‘an imaginary of knowability, in which it seems everywhere there is a capacity to know.’17 Thus, the imaginary sets up the common beliefs about the construction of knowledge and the protocols of access. The problem with the implementation of such a control mechanism in the context of the radical collapse of the cost of computation, however, is that any attempt is thwarted by information overload. This makes it important to consider the limit to how much knowledge stakeholders are capable of acquiring and processing as they get practically involved with negotiating the problems within the problem space of production – the cognitive load.
Cognitive load is associated with the total amount of mental effort exerted by the individual’s short-term memory while engaging in a problem-solving activity. As discussed in Chapter 2, the basic attributes of such activity are present in the problem space as the givens, the goals and the operators. During problem-solving, as psychologist John Sweller observes, an individual creates an inferential mesh to capture the available operators that promise coherence between givens and goals. The process demands that the individual simultaneously considers many aspects of the process, such as the current problem state, the goal state, the relation between the problem and the goal, the relation between any operators involved, and if the problem consists of many sub-goals, any updates due to the goal stack as the problem-solving goes along.18 Having to keep all this information in the short-term memory at the same time increases cognitive load. Furthermore, problem-solving can involve additional steps. For example, if the goal is unknown, the problem solver needs to make a series of abductive leaps into the unknown, a process that involves an intense period of learning about the essential structural characteristics of the problem space prior to any specific goal allocations. For this reason, while being creatively stimulating, abduction can be a taller order on the solver’s attention than regular means-ends inferences.19
Some of the factors that increase the complexity of the problem space of production are, as Callon observes, of the computational nature. They can involve software systems in the form of domain conflicts or the institution itself, in terms of its social dependencies. The former introduces new, disconnected bodies of knowledge, while the latter risks disrupting existing dependencies or creating new ones, the result for the agents in both cases being an increase in computational load associated with building new connections. Some examples of risk factors are tightening of competitive constraints, escalation of changes in production outputs or services that would demand faster adaptation or the re-organisation that brings new teams and specialisms that increase the heterogeneity of workflow processes or inventory.20 Speaking more generally, the criteria of the problem space, which are split for the present study into requirements, acceptance and customer value, can be more varied and specific to division or initiative. Whichever the factors are, the change they introduce is complex because it moves simultaneously along the two axes. It is also computational because it informs the procedural pattern of agent behaviour. On the one hand, the change increases the number of variables that have to be accounted for to understand the behaviour of the system. On the other hand, it intensifies their nonlinear interactions.21
In DevOps, cognitive load balancing is seen as the risk mitigation tactic which helps to avoid situations where the excessive amount of responsibility makes the work of the team perforated as they switch between increasing amounts of concurrent processes. It deals with the notion of the domain, which implies that the team members are located within a specific set of situated knowledge, which helps to prevent crisis events associated with the acquisition and processing of new knowledge, such as cognitive shocks. A cognitive shock should be defined in light of the present thesis’ view of complexity as a production failure caused by the disruption in either of the two aspects of routine cognition of the production system circuit. On the one hand, there is a limit of communication throughput where multiple individuals are involved, and on the other hand, there is a parallelism of individual activities, when cognition is carried out within one mind. The latter aspect poses a limit to how much knowledge integration one human mind can carry out at any time. To draw an example from Sweller, since the human short-term memory is limited, the cognitive load increases whenever problem-solving requires storing a large number of items within the short-term memory.22 This limit is higher when the system consists of many minds, however when multiple individuals are involved in problem-solving activity, there is a limit on the communication bandwidth among the independent minds that cognition is distributed.
Cognitive shocks occur when the agents have to assimilate excessive knowledge inventory, such as when switching between the domains, as indicated above. The disruption occurs whenever the knowledge about the inputs that the agents need to transform the incoming data into the outputs do not have any familiar or regular patterns. Patterns may be lacking, according to Matthew Skelton, because the spheres of knowability between the domains vary, particularly in the production of such complex artefacts as software systems, which may deal with numerous domains containing little or no compatible knowledge patterns that the agents can use for differentiation and integration.23 Skelton recognises intrinsic, extraneous and germane types of cognitive load agents usually deal with in software production. Intrinsic load deals with the acquisition and processing within the immediate vicinity of the agent’s location in the problem space: libraries, languages, classes or plugins. Extraneous load comes from environmental pressures, for example in component deployments or integration of components into the system, or use of testing suites. Germane load pertains to the tasks which require new learning outside of the agent’s immediate area of familiarity, for example, anything related to the business domain that the components are delivered into, such as cross-service compatibility considerations.24 Load balancing splits the different types of load to the duties of different teams, that either align with the technology stream or with the domain. Intrinsic load deals with the internal issues of the domain. It has the least impact on the overall topology of the problem space since all of the complexity is encapsulated within it. The other two are related to cross-domain processes, which means that the boundaries have to be carefully navigated to avoid cognitive shocks.
The key challenge in the situation of escalating change is that there is a demand for agents to constantly switch between the different kinds of cognitive load, from intrinsic to extrinsic to germane, and simultaneously update the whole knowledge stack to bring it back in sync with the new standards or frameworks associated with the changed processing and transmission capacities. The change in context requires re-indexing of the production system’s components to address the evolved set of external stimuli, as per Ashby’s Law of requisite variety and mapping it to its existing EIAC – the appropriate codification and abstraction processes. Such was the case in my empirical study at JX, the online publishing platform mentioned earlier. Following a critical security incident, it was decided to carry out the system migration process to AWS public cloud. The migration meant an improvement in the system’s traction because it provided better control over its resources and allowed it to deploy frequently, thus maintaining a good rate of change. It, however, also meant a substantial upfront investment to be able to ensure that new knowledge is compatible enough with the existing epistemology. This had occurred in the JX production team during the switch to AWS, albeit with no considerable impact on the delivery, since the appropriate onboarding procedures were in place. Still, in the aftermath of the migration, the production routines had to be re-learnt because of the introduction of new tools such as Jenkins for the deployment pipeline management, and new approaches to organising branches and releases in GitHub. It could be predicted that in cases where the change is more disruptive than the adoption of a new cloud service, it may not be possible to avoid, resist or predict the cross-domain cognitive switches within teams, which may lead to escalating disruptions in delivery.
Beyond the complexity caused by the frictions between the domains, another aspect of the cognitive pressure that the knowability governance needs to account for is the strong association between computational and social dependencies within the problem space of production. Since knowledge is something that has to be assimilated in an explicit event of learning, any discontinuities in social interactions may lead to spikes in cognitive load, which makes any collective endeavour within the organisations a computational as well as social occurrence. Such are the negotiations between stakeholders, which can be considered computational events in that they follow specific protocols or routines. Any computational event presupposes communication between the team members. More specifically, if one part of the computation is the responsibility of one agent, another part can be the responsibility of a different agent, depending on how the knowledge is diffused. Something that begins as a design job can later become a development job, and later yet, an integration or testing job. Regardless of team topology, teams and domains are closely interlinked, computationally as well as socially. As cognitive scholar Edwin Hutchins observes, competent load balancing is linked to the effective managing of dependencies because each part of any problem negotiated is not only a computational event, but is simultaneously a social message.25
This means that the resilience to complexity within the organisations, including the ones that employ topological strategies to design their production lifecycle, depends, to a large extent, on the cohesion of the social structure. The reliance on social dependencies can be so strong that it makes Hutchins question whether it is more valid to say that car production is the primary outcome of the labour of the car factory workers as a company department. For all they know, the primary role of the organisational form could be to produce a specific social dependency schema, with cars being an additional benefit, more relevant to the model of the market involvement of the business, rather than to the organisation itself.26 This notion is also reflected in the value-based market relations, which, as Marx develops in Volume One of Capital, result not only in the output of commodities but in further reinforcement of the classes of the capitalist and the wage-labourer. Marx observes that the capital produces ‘not only surplus-value, but it also produces and reproduces the capital-relation itself’27 In other words, since the capitalist mode of production cannot be interrupted in the interest of a continuing generation of surplus value, the production of commodities always includes the production of the social misbalance that makes it necessary to continue the production of commodities. Reproduction of social relations of production in a software production system falls squarely in the purview of DevOps. This has to be the case due to the requirement of auditability, which means that any relations that are not recorded in the form of EIAC, and are not deployed and integrated continuously, are vulnerable to the complexity effects. This makes it necessary to address the auditability consideration of scalability.
Fractality and scale-free systems
According to the thesis’ earlier observation, whenever changes are introduced into the system, the system tends to respond with the complexity increase. Such an increase presents a problem for planning and review, bringing uncertainty into the audit practices, which in turn threatens to halt production efforts. This means that keeping things auditable is a requirement which can be resolved by applying the additional work aimed at continuously simplifying the system. Such a method, however, may appear unsustainable in the face of exponential change, since, together with the expansion of the system, it would require equal rapid expansion of review and refactoring efforts across the many of the system’s components that suffer the complexity effects. As we saw earlier, the production method that is capable of addressing the ruptures caused by expansion is thinking about teams in terms of their topology. The related terms, a scale-free or fractal system, coined by the management theorist Bill McKelvey to describe the system’s self-preservation mechanism,28 can be used to draw a parallel between the processes within complex systems understood more generally and the software production system behaviour in the context of continuous and unpredictable change introduced to it.
Following up on the fractality notion of post-ANT critique established in Chapter 2, the scale-free principle works with complex phenomena, such as systems, in a similar way through the patterns of self-equivalence across their various scales. Fractality, as Pierpaolo Andriani and Bill McKelvey explain, is the self-similarity of constituent parts that could be codified via the patterns that echo the whole, thus making it possible to trace their attributions.29 Even though the agents have different tactics in response to the stimuli unique to their contexts, what appears important to the scale-free construction is the matching strategic principle.
While Fig. 17 illustrates the assimilation of knowledge by the individual agent, Fig. 18 aims to clarify that a general principle of how the organisations and their parts relate to the software system remains unchanged in different levels of the production system. On the left of the diagram is the team level, where all of the agents are co-located in relation to one another and to the software system through the mediation of the problem space. Zooming out to the organisation level, the same pattern is present in the arrangement and interrelation between the teams. On a larger cross-organisational scale, the pattern is still unchanged, and all the organisations that use the same software system are linked in the same way. Arguably, the problem space universally connects not only the agents, teams and organisations but also all of these entities across the boundaries of organisations, as Chapter 4 deliberates in the discussion of distributed collectivities.

Fig. 18. The fractality of relations across the different organisational levels.
Translated into the terms of the stream-alignment paradigm, the general strategy described by the common organisation pattern is the key stream that the production team aligns to. Depending on the fluctuation of complexity, the team construction changes on a sliding scale, not dissimilar to the antifragile architecture of real-world buildings in the areas of seismic activity designed to absorb the impact of earthquakes. In the moments where the stream-aligned team encounters issues which it cannot address in its default shape, an incident is opened, and it gets rapidly associated with relevant non-aligned teams, and correspondingly returned to its usual shape after the incident has been resolved. All three types of non-aligned teams can be involved in different capacities – platform, subsystem and enabling teams.
The platform team works alongside the stream-aligned team and provides the supporting environment in which the stream runs, rather than the stream itself. It thus joins forces with stream-aligned teams in cases where the platform updates or other changes may interfere with the performance of the application layer. Enabling teams provide research services to guide the aligned team through any middle-scale complexity incidents. The subsystem team gets involved when the stream-aligned team encounters something that either was not a part of the system before, or something disruptively new that has never existed altogether. In this case, the complexity presents a real threat to system performance and thus the whole section of work is split out to be handled by a subsystem team that is focused on that particular technology, leaving the stream-aligned team to continue providing the service to the stream without interruption. Once the work on the complex component is done, it is either integrated into the stream with some additional retraining or reconfiguration of the stream-aligned team, or via the API, in which case the stream-aligned team never requires the new skills. In both cases, the complexity effects are exhausted before they have a chance to cause any stress in production. The scale-free approach circumvents complexity by limiting the agent involvement to simplifying the level of the abstract schema, regardless of how much change the system has to go through. What is required of the organisation is to develop a unified strategy and apply it throughout all levels, only focusing the maintenance efforts around the cases where the change dynamics cause inconsistent deviations. Just as long as the principle is homogeneously applied throughout the system, it seems enough for the auditor to use it to be able to review as many system parts as it is necessary, without an exponential increase in time and effort.
The parsimony principle of agent knowledge acquisition
The important factor in keeping things simple within the production environment is a trend towards parsimony that the agents undertake. Such a trend is related to the overarching reasoning informed by Ashby’s requisite variety law discussed above and comes as a protective mechanism which aims to mitigate the risks of excessive data processing in cases when the problems present exponential computational demands.30 It implies that throughout their dealings with the outside environment, the agents would always tend to find response tactics that would match as closely as possible the external impact. This implies that those systems that overreact and expend too many resources on inadequate responses head towards disintegration. Likewise, those systems that do not respond enough tend to gradually fossilise.31 Agents achieve balance through the two-fold tactics of differentiating and integrating knowledge. The logic behind differentiation is that agents treat knowledge as a low-energy resource, which means that they tend to prioritise accumulating and using data, rather than more scarce resources of time, space and energy. Unlike the latter three, knowledge, once acquired, can be re-used without any losses to its quality or additional investment as many times as required, for as long as the inventory it pertains to continues to be relevant.
The use of knowledge, albeit less costly than more scarce resources, can be further optimised by differentiation, which the agents achieve by codifying it. Codification is a process of creating categories that classify the states of the world to better grasp the relationships between them. It aims to further drive down the computation costs by identifying the patterns within the incoming data that would allow splitting the information from noise. As Boisot observes, it works ‘by extracting relevant information from data—that is, by exploiting and retaining whatever regularities are perceived to be present in the latter that would help to distinguish relevant phenomena from each other’32 In other words, complexity is reduced by creating structures, locating the patterns that make it possible to create any degree of predictability. A well-codified knowledge inventory greatly reduces time spent looking for the required materials, however, can require a considerable upfront time investment. Staple production housekeeping practice such as writing technical documentation is a good example of codification that has to be carefully weighed against its potential future use. Quite often, the effort of writing up a comprehensive documentation can exceed its benefit, since much of what it describes can be learnt by using the functionality. Furthermore, if the feature is highly perishable, documenting it can be a waste of time altogether. In my fieldwork, I’ve come across a case where the documentation had been written for the library which later had been decommissioned in favour of a different one that had proven to be a better fit for the system. The lesson learnt, however, was that upfront spending is nevertheless worth it in most cases, for at least two reasons. On the one hand, it’s best to document early while the memory is fresh. On the other hand, it is not entirely possible to predict if documentation might not be used, in any case, and thus can be a lesser risk than keeping knowledge in the undifferentiated form which might present a difficulty to make sense of later on.
The second parsimony move undertaken by the agents, integration, is based on abstraction, a term which is used here in the sense of treating things that are different as if they were the same.
Thinking about abstraction as the treatment of difference, such as in the view offered by philosopher and sociologist Alberto Toscano, may help to relate abstraction as a parsimonious move to Barad’s agential cut together-apart, which also thinks about the effects of difference.33 To Toscano, abstraction helps to treat the difference between the multiple views of the phenomenon of high internal complexity by bringing together the effects of difference in the form of a unified determination.34 Further adding Boisot’s optic, abstraction can be seen as acting upon the codified results to create a tighter set of categories that pertain to a specific classification task at hand, and, as is the case with an abstraction of any other kind, it can be of a higher or lower level of generality, depending on the classification aims.35 In the integration move, the previously differentiated knowledge inventory is mapped to the existing epistemic infrastructure. Where the knowledge and the infrastructure are incompatible, the infrastructure operates as a topological machine: it is viscous enough to be adjusted, but also able to condition the incoming data on its deeper abstraction layers – this is best illustrated with an infrastructure tool, such as Jira.
Atlassian Jira is versatile enough to provide a framework for opening support tickets and to set up the many fields and workflow stages each ticket will be differentiated by, and this plays a crucial role in both differentiation and integration processes. The main ticket types in Jira are stories and epics: epics are used to group stories together into larger shipments. Each of those types will use different screens to capture data. Similarly, workflows define which transition steps are appropriate for the story in consideration. Most workflows will have basic stages like To Do, In Progress, Blocked and Done, which, in turn, affects which screen and field configuration schemes are active. In the integration stage, the lower abstraction details of Jira can be adjusted – for example, if some additional fields are required to log in the project-specific information, they can be added via the Jira administrator interface. Some of the more broad infrastructural considerations, for example, the fact that the task has an ‘Open’ status when it is created and has to transition to ‘In Progress’ status to end in the ‘Closed’ status, is hardly a matter for debate or adjustment.
There are three interested parties in ticket writing, usually appointed in the industrial research as the firm, its employees, and its customers, and specified for the present study as production teams, business owners and users.36 The Jira ticket is a contract that binds three types of parties together through the acts of gathering requirements, setting up the acceptance criteria and definition of customer value. Tickets as discrete entities also allow being grouped in different combinations, which may reveal various patterns within the problem space, which informs staff on planning, as well as opening very specific avenues for audit. To retrieve the relevant knowledge, Jira provides a search field which goes beyond the usual graphic user interface (GUI) option and can be accessed through writing in Jira query language (JQL), which uses regular expressions and boolean logic similar to MySQL and other popular query languages.
The possibility of querying the problem space of production makes Jira a diffractive topological machine, in the sense that it provides conditions for automatic production of spatial orientation for problems described in JQL. To retrieve the topology of the problem space, a collection of support tickets based on any field value, parameter, condition or any combination of field values, parameters or conditions is stitched together as a continuous plane – or to use Barad’s terms, the symbolic-material becoming of the problem is diffracted by cutting together-apart as a unified move. To begin with, the tickets are separated from the infrastructure that catalogues them, and then stitched back together according to the rules of their engagement and appear as search results. For example, the following query will return a list of bug-related tickets that Jira has records of, where the work either has or has not been started, arranged by their creation date:
issuetype in (Bug) and status in (Open, In Progress) order by Created DESC
The filtering, however, is only as good as its user experience and the attributes of the filtered content itself. Research using Jira has proven to be easier over the years of my fieldwork than any of its analogues, due to the accessibility of all the attributes, such as labels, statuses, component and cross-reference links, dates of creation and completion. All of them can be addressed in JQL, and thus, it is only a matter of Jira users’ ability to log the issues with relevant input parameters that ensure the accessibility of the archives. With all of these parameters to consider, rigorous coordination between Jira and the negotiation channels of the problem space of production is paramount. For example, it is good practice to agree on Initiatives, Epics, Components and Labels on an organisation-wide level, so that JQL queries would return consistent results throughout the different organisation’s departments. In other popular systems such as Notion or Trello the filtering is rudimentary to the point of frustration – for example, it is only possible to search the recently created tickets or by ticket name through the graphic user interface (GUI) with no option for regular expressions, which makes them much less accessible and therefore riskier to use in the situation of complex negotiations around the architectural and the political categories of the problem space composition.
Complexity and distributed governance
In correspondence to the previous section’s assumption that organisations cannot evolve as quickly as the technology they utilise, this section aims to understand why, and what are the implications for governance. To do that, the section starts by revisiting the notions of systemic change and momentum as the two counteracting organisational processes. Change and momentum, the two dynamics at the core of the production system in software capitalism, are taken here together as the two opposing forces that adaptive governance has to keep in balance to be able to maintain the system’s traction. While change is something that enables the organisation to adapt to its competitive environment by introducing new parts to the production process, momentum is something that keeps the cohesion of its existing constituent parts. Upon further examination, it becomes clear that beyond the vested interests of stakeholders involved in the production, there are specific material conditions that resist rapid change.
Adding on to the discussion of momentum in Chapter 1, the two factors help elucidate its strategic meaning within the organisation. On the one hand, any decision that an organisation takes also narrows down its future strategic choices. Decisions are seen as long-lived assets, designed to bring value over a long period of time. After having taken a decision, the organisation tends to commit to it, further implicating it into its cultural and governance fabric. On the other hand, decisions have consequences for the regime of governance. Understanding those consequences may help clarify why the adoption of distributed management or self-organisation-based control models appears to be appropriate for creating auditable organisational environments and does not act instead to dismantle the production system altogether.
Momentum as resistance to change
In terms of decision-making, momentum is manifest as the tendency of commitments that the organisation takes upon itself to become a part of the protocol, which comes to shape its future strategy. The change dynamic is not necessarily the problem in itself; however, as Max Boisot observes, it contains a risk because the change is often path-dependent and irreversible.37 What this means is that every decision that the system takes acts to close off the possibilities for some of the alternative scenarios, as they become too costly or come into conflict with the effects of the previous change. Herbert Simon describes such commitments as sunk costs, in view of which any rapid adjustments are not as profitable as staying with one decision, which usually promises long-term gains.38 The fallacy of sunk costs, to Simon, makes the investments made in the past a background that the new decisions have to be evaluated against,39 or, in other words, under the increasing weight of past decisions, the system proceeds along a certain path that makes it further determined in a specific direction. Furthermore, often changes cannot be reversed, which may cause a problem in production when the changes cause system failure, or on the side of management, who anticipate the failure and are reluctant to make the change, preferring to postpone the decision instead. Putting the decision off to a later moment usually assumes that the decision can lead to good outcomes under favourable conditions, and to poor outcomes when the conditions are not that supportive.40 In the context of rapid and radical change, however, no easy assumption can be made as to whether the environment will grow more hostile or more favourable in the future, and therefore is no lesser risk, particularly if there is no wider environment forecasting programme.
In the second place, there are real-life factors that make formal architecture more resistant to change as compared to strategy. This kind of resistance accounts for the time and effort it takes to actually implement the change – for example, any practical human resource dealings with staff hired on various contracts, but also the time it takes for the staff’s personal beliefs, including shared organisational values, to accommodate the policy updates. Even after any changes to the strategy are written down, the cultural trends take time to adopt them. Simon comments on this that during its operation, each organisation acquires sunk assets, which can come in the form of specific know-how – ‘the way we do things around here’, which comes together with goodwill – community-like relations between staff that aids communication, and is not easily transferable into a different activity.41 The combination of these factors creates a particular implied notion of momentum, which might not be made explicit in the organisation’s policies or technical documentation, but instead tacitly accumulates over time to create a shared understanding that any change in objectives would entail a decrease in efficiency associated with loss in some of the sunk costs or assets, as well as a potential erosion of goodwill. Such understanding of an organisation’s inertia gives a new meaning to the interpretation discussed in Chapter 1 because, rather than thinking about how technology shapes society, or in this case, the organisation’s production lifecycle, it aims to understand in which way the inability to communicate the knowledge is treated by the organisation, and what kind of risk it presents. Such knowledge is often referred to as tacit, and a more detailed description of this notion at this point will help clarify the character of the organisation’s treatment of it.
Momentum and tacit knowledge
Within the production lifecycle, information is located explicitly in the form of documentation, which is meant to reflect the epistemic infrastructure but may have gaps depending on how much priority the organisation gives to documentation work. Information implicitly embedded in the components of the infrastructure itself can be more reliable. Agents apply conceptual filters, such as specific context informed by the support ticket, when using the information found in the organisation of the system’s environments, in its configurations, in the source code comments or in anything contained in the code repository. In their engagements with the epistemic infrastructure, the agents accumulate or adjust the expectations they may have about the kinds of knowledge they gain about the system. Lastly, as the agents form a specific relationship with the kinds of data and information they usually encounter in the system, they acquire a mental model that enables them to create the situated knowledge, based on the expectations.
Faced with a change that comes from outside of the organisation’s sphere of control causes a loss in momentum because the culturally constituted ways of doing things with the specific combination of the organisation’s skills and technology are no longer seen as viable in the new production context. As we saw previously, momentum is instructed, on the one hand by the business requirement of getting the software product out into the market as soon as possible, and on the other hand by the efforts of corporate governance to pull the controlling protocols together so that it continues to be possible to manage the risks and ensure that no regulations are violated or that no quality issues lead to the loss in sales. The key issue is with maintaining the balance between the parts, whichever condition they are in. An important factor to momentum is that it is something that the whole organisation works hard to build up, often, as the case study CS15 shows, as part of establishing the basic initial communication patterns. Thomas P. Hughes emphasises that at any given point in the project, the degree of its success is informed by the degree that the various parties are invested in its different aspects. This means that any organisational initiative is underpinned by the web of interests, including funding bureaucracies, engineering leads, and any executive or trustee boards that are going to be affected by the changes in production. Therefore, it is only natural that where a certain existing momentum already warrants predictable outcomes, the disruption in the way of things can be met with resistance. While the momentum may offer rapid execution along the well-trodden paths, the path dependency is precisely what presents a problem when dominant logic is confronted with ongoing change. As Max Boisot demonstrates, such logic introduces friction that makes the cognitive switches harder to achieve, and while the persistence of inertia may look like a benefit from a neoclassical economic standpoint, in the face of emergent qualities of the problem space it is, in fact, a non-equilibrium phenomenon.42
The innovation proposals that the existing institutional framework is capable of resisting are something that can enter the organisational imagination in some form – there could be cost estimates, roadmaps or architectural blueprints. The extreme organisational rupture is caused by more serious tectonic shifts that are not proposed or charted at the inter-organisational level, simply because the construction of the problem space does not account for something that lies outside of the problems it had been used to negotiate up to the present moment. There are no prior givens, goals and operators that can be utilised to tackle radically new problems, and therefore the activities of problem space of production become entangled with the abductive leaps that are taken as the last resort of bridging the gaps of insufficient knowledge. However, as this chapter’s earlier discussion of cognitive load demonstrates, depending on how large the unknown terrain is, abductive leaps may take considerable time to investigate the new contours of problem space. The issue is, that in situations of extreme complexity, the scales of innovation can be so vast that the search time takes long enough for the system to lose traction where it previously had it. In this case, extreme organisational rupture occurs, leading to the inability to move forward without a substantial re-organisation.
While the situated knowledge factor accounts for the topological quality of knowledge, its tacit quality points to the degree of its entanglement in production practices. To the philosopher and economist Michael Polanyi, who closely engaged with the notion, tacit knowledge always involves more than anyone can say and is to a greater or lesser degree enmeshed in skills and know-how. It is central to the problem to have an element of discovery, ‘the intimation of something hidden.’43 In other words, tacit knowledge benefits the affective side of communication between individuals involved in production in the same way as explicit knowledge benefits effective business operation. Since tacit knowledge is personal, context-specific and derived from direct experience, it is inseparable from communication, which is often an integral part of practice rather than verbal or expressible by other external means. The association with practice makes the notion of tacit knowledge important for my argument since implied property means there is no associated effort of making it external for production, which, in turn, means that the use of tacit knowledge adds a great deal of momentum. The knowledge which is tacitly present as part of daily production practice does not require meetings, onboarding, emails or technical documentation. It is simultaneously a part of the organisation’s design and its culture.
For this reason, tacit knowledge enables the parsimony tendency within the agent’s behaviour, in the sense discussed in the previous section, as something that does not require integration efforts. In some instances, tacit knowledge does not have to be something that cannot be communicated – for example, where participants are placed within the same context, the knowledge that could otherwise be written down in the company wiki or sent via chat or email, under the circumstances can remain unsaid at all. The knowledge that remains unsaid, however, also presents a potential business risk since the inability to communicate, which is a benefit in the existing context, may appear as a bottleneck if the workflow is changed, or people are no longer involved with the business. This means that such momentum of Simon’s sunk asset of goodwill should, as we saw in the description of Fuller and Goffey, be met with resistance by the organisation, as a hindrance to the circulation of knowledge assets and adds to the expenses of differentiation and codification.44 This additional benefit of tacit knowledge to operations is not always recognised on the executive level, which may have a hiring strategy that does not account for it. The case study CS15 – an archival project case study in the Appendix – illustrates the extreme rupture of the problem space of production that was caused by another reason, the change in geopolitics, which, however, has had a similarly disruptive effect on the production process, and therefore can be looked at in this context.45
The case study looks at the situation that occurred in the aftermath of the abrupt halt of the production process of the publication (JX) in early 2022. The stop press had been made necessary by the changes in the company’s strategy which were caused by the Russian invasion of Ukraine in that year and the rapid severance of international economic and cultural links across the region. Six months after ceasing publication, JX came up with the requirement to redesign the system for the new purpose and re-launch what used to be a media channel in the form of a digital archive. I was involved as the project lead both with some of the old team and new staff hired for the production of the archive project. One of the challenges, in this case, was that when a part of the old team was gone, a good deal of the production momentum was lost. Even in the presence of documentation and the continuing support from myself as the bearer of much of the previous production knowledge, the new team members had to begin by applying conventional thinking to the system which to them was completely new. This has led to some frustration and misunderstanding, initially from my side, since when writing the briefs and commissioning designs, the idea was to save the effort and to re-utilise the existing system components. The lack of momentum in the new team, however, meant that it was not possible to simply start building where the old production team left off. Instead, lots of seemingly ready-to-use components, such as the top navigation, appeared easier to recreate from scratch, due to the now lost situatedness of the knowledge about how this component was embedded in the overall structure of the system. Having to recreate the components from scratch led to increases in the initial phases of the project, however as the system-specific mental model began to take shape in the minds of the new team members, the momentum had noticeably built up.
Empirical cases as above have instructed me on the field uses of abductive modelling as it develops in conjunction with creating the body of tacit knowledge. In situations of extreme organisational rupture, the agents have no other option but to go beyond the available evidence and start by generating hypotheses. To Magnani, whenever the stable ontological grounds of reasoning are shaken, the hypotheses tend to transcend the existing agreements between the paradigms, as in the scientific discoveries during the transition from classical to quantum mechanics, which were made through the use of abductive reasoning.46 In the realm of production, the abductive mechanisms are used in teams as a rule of thumb without much theorising, but rather with the aim to reach the point at which the hypotheses are developed enough to start the testing iterations. To maintain traction, the abduction needs to take into account any existing components, such as databases or environments. Databases are usually robust enough to survive complexity spikes and are expected to be highly regular, subject to the efforts of the system’s database architects, however, can be highly opinionated. In one of the field cases, I learnt that the out-of-the-box CMS, including the one used at JX, are usually not fit for most production environments not native to them, since they came with pre-designed databases that fit their original needs, and are usually incompatible for other users whose needs might differ. In other words, every production system comes with its own assumptions about the format in which the data comes in. While the complexities of such kind are accidental, they may allow making a case that the accidental complexity is where the most crucial complexity cases may often be found.
Concluding the section on change and resistance, it should be noted that while every change may meet resistance within the existing organisational structure, it is particularly important to account for the changes that the system is not prepared for, due to the inability to account for them, since such changes have more potential to bring the system into misbalance. An organisation may find itself under pressure to change in response to the changes that occur outside of the production context under consideration, and therefore without any coordination with the organisation’s own governance or audit planning. For example, change may occur in the wider ecology of the production system, such as updates to the operating system or third-party or open-source libraries, or changes may occur in the market domain caused by the adoption of the new technology by the competitors.
Returning to the two examples we saw earlier in this chapter, the AWS migration project and the Archive project carried out by the new team after the project was officially closed, can be seen in this context in terms of their responses to the radical external changes. In the former case, because the migration was performed as part of the crisis mitigation measures, it was carried out without particular regard to the organisation’s overall internal planning. This had placed the additional complexity stress on its production system because the utilisation of the CloudFormation, the infrastructure as code service which comes as part of the AWS offering, is generally associated with a more specialised DevOps treatment compared to the system JX used before. This, in turn, implied an additional cost consideration, which in this case could not have been done in advance, and therefore caused tensions in the organisation’s production budget planning.47 In the latter case, where the team cohesion was ruptured in relation to the major and long-lasting geopolitical trend, the primary focus has been on building the body of tacit knowledge based on technical documentation and gaining enough traction to deliver the required updates to the product while trying to abstract, circumvent or delay any further complexity dealings, such as code review, refactoring and regression testing to a later stage.48
Specifics of coordination in adaptive complex processes
As the discussion of the cognitive load suggested earlier, due to the limits of their capacity to assimilate new knowledge, the agents seek to position themselves out of harm’s way of complexity. Beyond the tactics of differentiation and integration, the agents tend to further reduce the complexity effects by employing the distributed principle in their processing efforts. As Max Boisot explains, the distributed character of processing means that the agents, otherwise scattered within the boundaries of the same problem space or the same domain, come together to participate in the event of problem negotiation on a case-by-case basis. Furthermore, distributed cognition works equally well both in homogenous and heterogenous epistemic environments, meaning that it is not uniquely linked to the common knowledge that the agents may have, but also to the differences in their knowledge – the inconsistencies here facilitate self-organisation since the diversity of understanding of the issue at hand may lead to faster problem-solving.49 The activity of abstraction that the agents carry out is differential, meaning that it is not intended to express any generic objects suspended from differences, and is close to Marx’s real abstraction, which, as we saw in Toscano earlier, arises from the varied determinations of agents in the historically specific relation of production.50 The agent coordination that is based on their differences makes it imperative that the agents discern the patterns within each other’s behaviours to maintain the group cohesion, as well as the patterns of their environment. The regime of coordination that enacts the rules for such mutual adaptation should therefore be more precisely defined as adaptive governance. Such governance is characteristically non-centralised and scale-free.
The rules enacted by adaptive governance comprise something that can be defined as protocol, a set of soft regulatory principles that do not imply administrative compliance, but rather define a management style and bear cultural value as something which is shared across the organisation and on a wider scale of a community of practice. The protocol’s relaxed applicability is necessary for it to be relevant in the uncertainty of complex production situations. More specifically, the advantage of the protocol is that it can be applied to both the practice and process. The practice is viewed by the administration as the enactment of situated knowledge accumulated in a specific community, where its members continue searching for new solutions within the boundaries of their domain. The process, in contrast, is the vertical spread of knowledge, which cuts through the various levels of situated knowledges. To illustrate the difference, it is worth evoking Adam Smith’s rich example of a pin factory one more time, albeit for a different insight. As we saw previously, the protocol of the factory breaks down the production of a single pin into the activities of separate workers, such as drawing out the wire, straightening it, cutting it, and so forth. The benefit of the division to practice is that each individual worker, once relieved from having to switch between different activities, can creatively explore and optimise the specific activity assigned to them. In terms of process, the pin as a result of collective effort is present as the guiding principle for all the subordinate production events and as a tool for quality assurance. In complexity management scholarship, it is usually acknowledged that away from the traditional centrally controlled manufacturing operations, most systems today, including the ones involved in complex production scenarios, are managed in a distributed way as clusters of local practices, while remaining auditable as processes through the main guiding principles.
More specifically, distributed governance becomes possible when three factors pointed out by Maguire, Allen and McKelvey are present: readiness for organisations to enter into a coordinated relationship, their sufficient connectivity that makes the mutual coordination possible, and abundant resources.51 The distributed system can thus be defined, via Azadegan and Dooley, as a system where there is no one source of ultimate authority, or even in the presence of a protocol it is the agent body that bears the most responsibility for decisions: ‘in a distributed control system a number of agents are responsible for sensing, interpreting, and controlling actions.’52 In real-world production, for example, as I discovered in my fieldwork, the scenarios were mostly mixed, with main strategic decisions coming from the key stakeholder, which was then met with resistance from the self-organised agent groups who may have found the decisions incompatible with the accumulated local knowledges. As the production process continued, the outcomes were further evaluated against the strategy, and the strategy would be adjusted, resulting in negotiated solutions that would allow effective delivery for everyone involved.
Chapter conclusion
This closing chapter of the thesis has looked at the governance implications for complex responsive production systems. The governance here appeared as distributed and operating not through any fixed hierarchy, but via the audit applied throughout the product system in a scale-free way. Such audit is necessary, in the context of complexity’s fluctuations, due to its ability to circumvent them by limiting its inspection to the organisation’s internal managerial structures, which, in turn, report on the performance of the self-organised agents’ associations. The chapter has explained such fluctuations as a necessary feature of software capitalism that comes from its fundamental tendency for the cost of computation to fall. Complex adaptive systems avoid internal hierarchy by maintaining instead a protocol, or a unified set of principles, for codification and abstraction. The protocol is cultural in that it springs from the beliefs shared by agents throughout the organisations and communities of practice about the ways in which the knowledge should be classified so that it could be searched, sorted and filtered by others later. The shared codification and abstraction beliefs, paradoxically, preclude the integration of knowledge due to the inevitable fact that some of the knowledge is present in its tacit form.
Therefore, the more complexity the distributed governance is presented with, the more non-transferrable tacit knowledge is generated by the agents locally, and, concomitantly, the more resistance to audit there is. While in this case, there might seem like a semblance between the centralised and distributed systems, it occurs for different reasons. In the centralised hierarchies, the inability to audit happens due to the presence of real-world limits on how much information the system can process and transmit. In the complex adaptive system, conversely, there is no problem with overflows and the stifling of reporting capacity here is intentional and, to use the Marxian term, appears as a feature of real subsumption of labour, that is, fully conformed and appropriated by the software capitalism production process. Tacit knowledge is produced as a means of creating scarcity within the system that otherwise wouldn’t have it due to its fractal character. While in its tacit form, the knowledge is difficult to scale across the system in the event of a complexity spike, it provides a great return on investment in terms of efficiency increase warranted by the momentum. When the agent’s abilities to codify and abstract are overwhelmed, they suffer cognitive shocks, causing losses in efficiency. At this moment, the knowledge is converted to its explicit form, making it possible for the organisation to create new business divisions and address any complexity effects. The capitalist valorisation mechanism, in turn, propagates to the team and organisation levels by increasing capital circulation in those new divisions. As the discussion throughout the chapters of this thesis as a whole has aimed to demonstrate, the new divisions may not have been required without the situation of artificial scarcity created for capital circulation.
References
Mezzadra and Neilson, 2019: 215. ↩︎
Humble and Farley, 2010: 417. ↩︎
Arthur, 2021: 9. ↩︎
Lury, 2021: 17. ↩︎
Boisot and Li in Boisot et al., 2007: 129. ↩︎
Boisot in Boisot et al., 2007: 160. ↩︎
As the roboticist Rodney Brooks observes, ‘a week of computing time on a modern laptop would take longer than the age of the universe on the 7090,‘ (Brooks, 2021) – which effectively suggests that the computation has lost at least that much of its cost. ↩︎
Engelbart, 1994. ↩︎
Azhar, 2021: 85. ↩︎
Ibid.: 101. ↩︎
Boisot and MacMillan in Boisot et al., 2007: 51. ↩︎
Boisot and Canals in Boisot in Boisot et al., 2007: 20. ↩︎
Boisot and Li in Boisot et al., 2007: 117. ↩︎
Brown and Duguid, 2000: 119. ↩︎
Brown and Duguid, 2000: 120. ↩︎
Lury, 2021: 180. ↩︎
Lury, 2021: 184 citing Thrift and Hayles. ↩︎
Sweller, 1988: 261. ↩︎
Ibid.: 260. ↩︎
Callon in Law and Mol, 2002: 191. ↩︎
Boisot in Boisot et al., 2007: 155. ↩︎
Sweller, 1988: 265. ↩︎
Skelton and Pais, 2019: Ch.3. ↩︎
Ibid. ↩︎
Hutchins, 2000: 224. ↩︎
Hutchins, 2000: 225. ↩︎
Marx, 1990: 724. ↩︎
McKelvey in Allen et al., 2011: 124. ↩︎
Andriani and McKelvey in Allen et al., 2011: 259. ↩︎
Boisot in Boisot et al., 2007: 156 citing Chaitin,Sipser. ↩︎
Boisot and MacMillan in Boisot et al., 2007: 65. ↩︎
Boisot and Li in Boisot et al., 2007: 88. ↩︎
Barad, 2010: 265. ↩︎
Toscano, 2008: 276. ↩︎
Boisot and Li in Boisot et al., 2007: 118. ↩︎
Callon in Law and Mol, 2002: 206. ↩︎
Boisot and Li in Boisot et al., 2007: 77. ↩︎
Simon, 1997: 148. ↩︎
Simon, 1997: 148. ↩︎
Ibid.: 137. ↩︎
Ibid.: 148. ↩︎
Boisot and Li in Boisot et al., 2007: 97. ↩︎
Polanyi, 1983: 22. ↩︎
Fuller and Goffey, 2012: 127. ↩︎
See Appendix CS15. ↩︎
Magnani, 2009: 33. ↩︎
See Appendix, CS12. ↩︎
See Appendix, CS15. ↩︎
Boisot and Li in Boisot et al., 2007: 101 citing Hayek. ↩︎
Toscano, 2008: 275, 277. ↩︎
Maguire, Allen and McKelvey in Allen et al., 2011: 15. ↩︎
Azadegan and Dooley in Allen et al., 2011: 421 citing Tunalv, Radner, Deshmukh et al. ↩︎